Between 1982 and 1983, Mitsubishi Electric announced the MELCOM 80 OFFICELAND models 500 and 400, which were the first office computers to feature a 32-bit architecture (the logical address space, however, was 24 bits, allowing for a 16-megabyte address space). These models came with DPS 10 as their operating system. DPS 10 was a groundbreaking operating system for its time. Based on the process management, memory management, file system, and other kernel operations of UNIX System III, DPS 10 offered the extended functionality needed in an operating system for business computers, including job management, database management, spooling management, terminal management, communication management, and other functions.
- DPS 10 had the following features.
- (1) File system
- Ordinarily, the UNIX file system managed disk space in blocks (DPS 10 used 2-kilobyte blocks), and disk I/O operations were performed in blocks via a cache in the main storage device. The DPS 10 file system, on the other hand, was equipped with a sequential data space (SDS), in which data records were physically located in sequence, apart from the blocked data space (BDS), which was managed in block increments. The inclusion of SDS enabled efficient large data processes frequently accessed by business applications.
- (2) Database management
- DPS 10 came with a unique database management system that operated on the file system mentioned above. Although the DPS 10’s database management system was able to organize files as sequential files, relative files, indexed files, and multi-indexed files that were backward compatible to DPS IV, its real achievement was the realization of relational databases that handled virtual files, which were mapped to multiple physical data records by means of logical data definitions, independent of the physical file structure. Relational databases were also designed to accelerate online tasks by using disk caches in main memory when these data files were accessed. Furthermore, by taking advantage of the sequentially created data files in the SDS mentioned above, large data files associated with batch processing, for example, could be input or output in large size without a disk cache if a single job had exclusive control to the files. This form of I/O processing greatly reduced the CPU overhead during I/O.
- (3) Job management
- For DPS 10, Mitsubishi Electric implemented a job management functionality on UNIX, which was essential for business computers. Job management on DPS 10 included a job scheduler, a job control language, a job accounting function, and an automated operation function. The job control language had a command language with the flow control such as conditional branches and loops that were seen in programming languages. DPS 10 also included a symbiont function (spooling control).
- (4) Programming languages
- DPS 10 supported COBOL and Progress II. It also came with the fourth-generation programming language DUET (later EDUET), which dramatically raised the productivity of management and information analysis applications and applications for data maintenance.
- (5) The GREO relational database processor and MSA
- The MELCOM 80 GEOC System 80GR, which was announced in April 1989, was equipped with the world’s first ultra-high-speed relational database processor called the GREO. By simply loading the GREO board, these office computers saw a three-times to 50-times boost in relational database processing speeds because computationally intense sorting was done in GREO at high speeds unloaded from the CPU. For DPS 10, Mitsubishi Electric developed a multi-stream architecture (MSA) to control the GREO processor. The MSA determined whether sorting, index generation, record extraction, or other processing that were frequently used by business applications were performed on the CPU or on the GREO processor, and controlled it. This selective control executed relational database processing at high speeds and maximized system throughput while avoiding the need to modify existing applications or job control languages.
- (6) Online transaction processing system
- DPS 10 was the first office computer operating system that supported an online transaction processing (OLTP) system. By using a queuing methodology, the DPS 10’s transaction processing system was able to process transactions from multiple terminals with minimum resources (in terms of CPU power, memory, etc.). This OLTP system was used for systems with over 1,000 terminals, such as ATM connections of a financial industry.
- DPS 10 K00 Version (with several extensions to the DPS 10) As office computers moved into the 1990s, they needed to have the performance and reliability of small to mid-sized mainframes in order to keep up with soaring data volumes, mainframe-downsizing demands, and developments such as end-user computing (EUC). For the MELCOM 80 GS700/10, announced in November 1992, Mitsubishi Electric, with the expansion of partner corporations and the latest semiconductor technology, developed a fully customized one-chip CPU on the scale of 1.7-million transistors and, through high-density mounting technology, dramatically expanded and improved the machine’s system architecture. The K00 version of DPS 10, which was developed specifically for the GS700/10, offered many improvements as well.
- (1) Extended hardware support
- The address space on the GS700/10 was expanded from 24 bits (16 megabytes) to 31 bits (two gigabytes). To match the 31-bit address space, DPS 10 K00 version supported up to 150 gigabytes in disk space, up to 2,048 terminals, and up to 384 communication lines.
- (2) Functions for higher reliability and the recovery management system
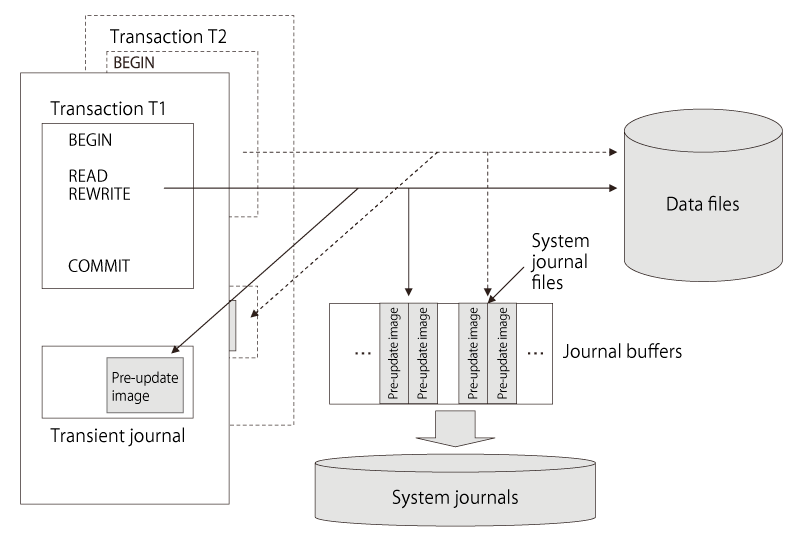
- The operating system offered native support for disk mirroring and a recovery management system as functions that gave higher reliability. What follows is a description of the DPS 10’s recovery management system. Many older office computer systems kept a transaction log of online tasks during the day and then updated the master files with batch processes at night. As a result, it was not difficult to recover databases even if the system went down. But as office computers began to be employed in larger and larger OLTP systems, they required full-fledged recovery methods capable of restoring databases on a per-transaction basis in the event of a system failure. For these reasons, Mitsubishi Electric developed the recovery management system (RMS) for DPS 10.